321 words
2 minutes
[CS5446] Reinforcement Learning Model and Abstraction
Model-free vs. Model-based
- Model-free: No model, learn value function from experience
- Model-based:
- Model the environment
- Learn/ Plan value function from model and/ or experience
- Efficient use of data
- Reason about model uncertainty
- But may have model bias
Model
- parameterizad by :
- state & action are known
- find transition & reward function (unknown)
- model learning to create model
Model Learning
- learn from past experience
- supervised learning
- to minimize loss function (MSE, KL-diverge)
Model
- Table Lookup Model
- i.e ADP
- cannot scale
- Linear Model
- represent tranition & reward function as linear model
- Nearual Networks Model
- i.e VAE
- Problem
- learning transition function may be difficult
- too many factors to learn from the environment
- Sol: Value Equivalence Principle
- Two models are value equivalent if they yielf the same Bellman updates
- learn latent mapping function
learn latent transition & reward function
- learning transition function may be difficult
Now that we have a model, how can we use it?
Model based techniques
- Goal: find optimal policy/ value using the model and/or the environment
- Direct model solving
- solve using MDP solvers
- i.e. value/ policy iteration
- uses the model fully (use as if it were the environment)
- ADP: learn a model and solve the bellman equation of the learned model
- Value iteration network: value iteration + NN
- solve using MDP solvers
- Sample-based planning
- use the model ONLY to generate samples
- don’t consider the probability distribution of the model
- apply model-free RL on samples
- Monte Carlo control
- Q-Learning
- but too time consuming
- Sol: plan for states that are relevant for NOW (planning for surrounding)

- Model-based Data Generation
- consider both
- real experience from environment
- simulated experience from model
- train model free RL with both experience
- i.e
- Dyna-Q

- Dyna-Q+
- Dyna-Q with exploration bonus
- Dyna-Q
- consider both
Frontiers
- General Value Function (GVF)
- generalize value function to predict any signals

- generalize value function to predict any signals
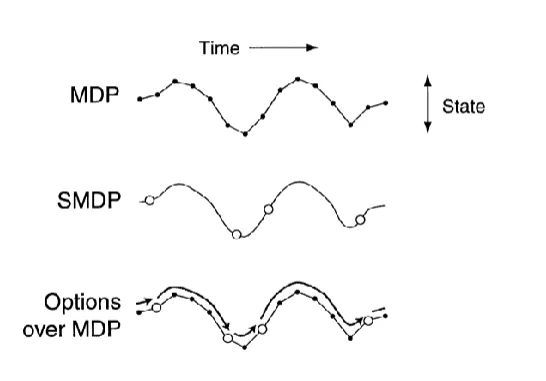
- Temporal Abstractions via Options
- hierarchical RL
- option
- (state)
- : a policy to follow
- : probability of terminating at each state
- Designing Reward Signals
- Problem: agent cannot learn until it reaches the goal (where the reward is)
- Sol: add fake rewards to make the learning easier
- Extrinsic reward: rewards from the environment
Intrinsic reward: rewards from the agent itself based on its internal state
[CS5446] Reinforcement Learning Model and Abstraction
https://itsjeremyhsieh.github.io/posts/cs5446-7-reinforcement-learning-model-and-abstraction/