508 words
3 minutes
[CS5446] Reinforcement Learning Foundation
Reinforcement Learning
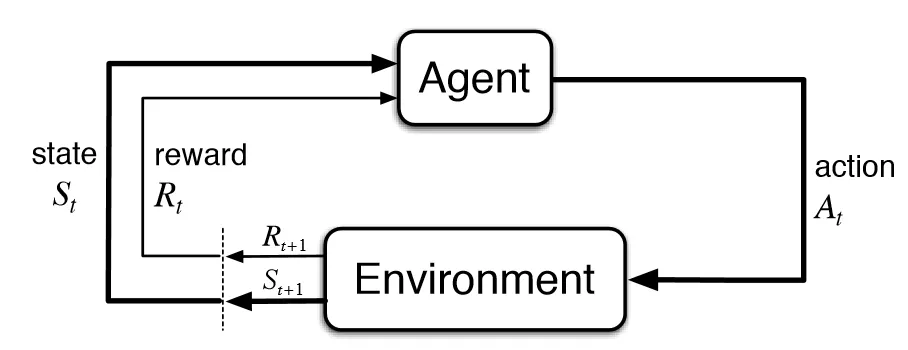
- Learning to behave in unfamiliar environment
- Environment is a Markov Decision Process
- relies on Markov Property (but doesn’t know what it looks like)
- Unknown transition function, unknown reward function
- Use observed rewards to learn optimal policy
Types of RL
Model-based vs. Model-free
- Model-based: Learn transition model to solve problem
- Model-free: Doesn’t learn the transition model, directly solve the problem
Passive vs. Active learning agent
- Passive: given policy → evaluate the value & find utility function
- Active: Learns the optimal policy & utility function.
- Needs to balance between exploitation & exploration
Passive RL
- Execute a set of trials using fixed (given) policy
- Learn expected utility for each non-terminal state
Model-based Passive RL
- Adaptive Dynamic Programming (ADP)
- Learn transition function through experience
- Count outcomes of each state, action
- Normalize to estimate
- e.g
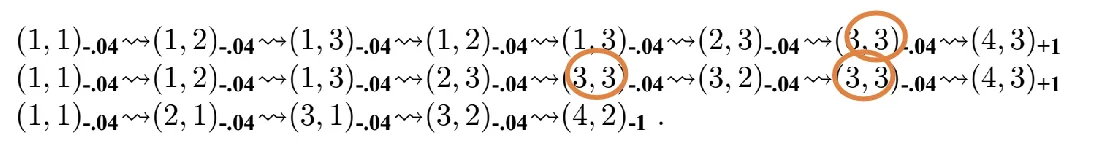
- Now we have the transition functions, we can obtain rewards for each with given policy
- Learn reward function upon entering state
- Solve linear equations with unknowns requires time
- Adjusts the state to agree with ALL successors

Model-free Passive RL
Directly learn the utility, doesn’t learn the transition and reward function
- Monte Carlo Learning
- Maintain running average of expected return for each state.
- If run many times → converge to true expected value
- e.g
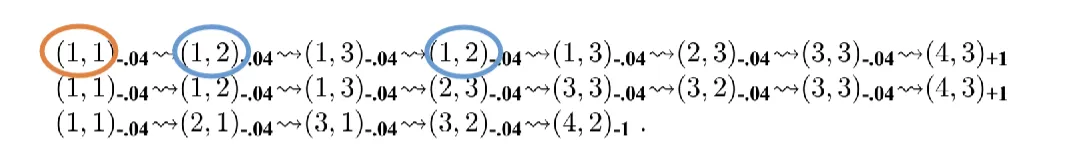
- For the first trial,
- Expected reward of (1,1) = 0.72
- Expected reward of (1,2) = 0.76, 0.84
- Overall (average),
- For the first trial,
- Different variences: first visit vs. every visit (of a trial)
- Slow convergence
- Learning starts only at the end of each trial (episode)
- Temporal Difference (TD) Learning
- TD target:
- TD error (term): TD target
- TD Error
- N-step TD: do estimate up to steps
- TD(λ): combine returns from different TD-steps
Active RL
Act optimally based on prediction of utility of states
- Goal: learn optimal that obeys Bellman Equation
Model-based Active RL
Learn the transition and reward function, then solve the MDP ()
- Active Adaptive Dynamic Programming
- Learn model with outcome probability for all actions
- Resulting algorithm is greedy
- Pure exploitation may not be optimal
- We need tradeoff between exploration & exploitation
Greedy in the Limit of Infinite Exploration (GLIE)
- a learning policy
- scheme for balancing exploration & exploitation
- ε-greedy exploration
- choose greedy action with
- choose exploit (random) action with
- lower ε over time , eventually becomes greedy (takes the optimal action)
Model-free Active RL
Directly learn
Monte Carlo Control
- Exploration function
- how greed is trade off against curiosity
- should increase with and decrease with
- e.g
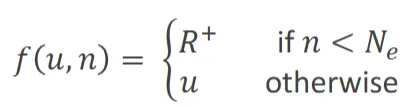
- : best possible reward
- : agent tries each state-action pair times
- Exploration function
Active TD / TD Control
Q-Learning
- Use optimal to estimate Q
- off-policy: estimate policy ≠ behavior policy
- Q-function: expected total discounted reward if is taken in with optimal behavior
SARSA (State-Action-Reward-State-Action)
- Uses TD for prediction, ε-greedy for action selection
- on-policy
- Waits until an action is taken, then update Q function
Comparison
| Passive | Active | |
|---|---|---|
| Model-Based | ADP | Active ADP |
| Model-Free | Monte-Carlo; TD | Monte-Carlo Control; Active TD: Q-Learning, SARSA |
[CS5446] Reinforcement Learning Foundation
https://itsjeremyhsieh.github.io/posts/cs5446-5-reinforcement-learning-foundation/