543 words
3 minutes
[CS5446] Markov Decision Process
Markov Decision Process (MDP)
How can we deal with uncertainty?
- A sequential decision problem for a fully observable, stochastic environment with Markovian transition and additive rewards.
Formal definition
- MDP
- states
- actions
- Transition function :
- satisfies the Markov property s.t . (Sums to 1)
- Reward function
- discount facrot
- solution is a policy: a function that recommend an action in each state
- Markov property: Next state only determined by current state & action
- Markov property simplifies real-world problems
- Reward funciton : need to balance between risk & reward
- Policy : for every state, map an action
- Quality of : expected utility of sequence guaranteed by performing policy
- Optimal policy : highest expected utility
Finite horizon:
- fixed time , then terminate
- Reward: sums up to
- optimal action may change over time Nonstationary
Infinite horizon:
- no fixed deadline, may run forever
- Stationary
- But R may be infinite, hard to compare policies.
- use discount factor , utility becomes finite
- Environment has terminal states, and policy guaranteed to get to a terminal state.
- Compute average rewards obtained per time stop
- hard to compute and analyze
- use discount factor , utility becomes finite
Utility of States
- reward of executing
- Bellman Equation:
- Optimal policy is the policy that maximizes :
- Q-Function : expected utility of taking a given action in a given state
Value Iteration
- repeatedly perform Bellman Update
- or
- to find rewarding value for each state
- initialize as , iterate until convergence
Policy Iteration
- Begin with initial policy
- Repeat until no change in Utility for each state:
- Policy evaluation: uses the given policy to calculate the utility of each state
- Policy improvement:
- find the best action for via one-step lookahead based on obtained from policy evaluation step
- Complexity: linear equations with unknowns
- Policy iteration may be faster than value iteration.
Online Algorithms
Decision-time planning
- for large problems, state space increase exponentially
- we can use Online search with sampling
- real time dynamic programming
- Monte Carlo Tree Search
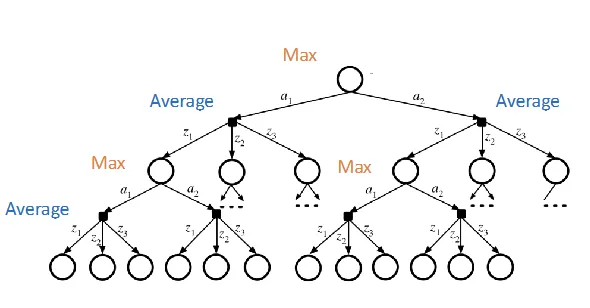
- keep the best actions at each state nodes
- tree size: , A is the # of actions, S is the # of states, D is the depth of tree
- With sparse sampling:
- sampling observations
- tree size:
- but still exponential with search depth
Monte Carlo Tree Search
Online search with simulation
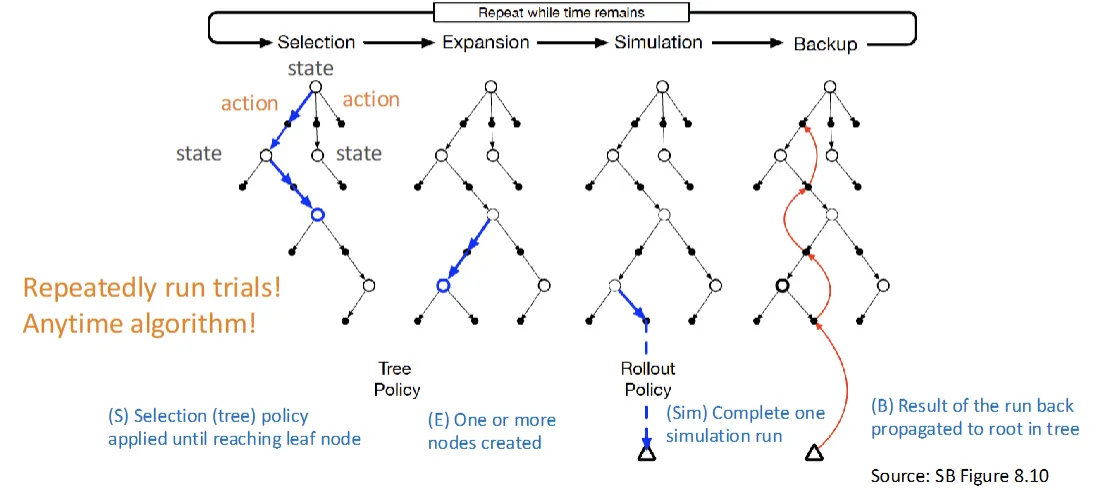
- Selection: select the leave nodes to expand
- Selection policy: Upper Confidence Bounds applied to Trees(UCT)
- is the average return of all trials (exploitation)
- : constant balancing exploitation & exploration
- : # of trials through node
- : # of trials through node starting with
- 也等於
- : the # of parent node been visited
- : the # of node been visited.
- : 贏的次數 / 嘗試的次數
- : 開根號 總次數 / 嘗試的次數
- Selection policy: Upper Confidence Bounds applied to Trees(UCT)
- Expansion: one or more nodes created
- Simulation: estimate the value of the node by completing one simulation run (run to leaf)
- Backup: update the result back to root.
[CS5446] Markov Decision Process
https://itsjeremyhsieh.github.io/posts/cs5446-4-markov-decision-process/