402 words
2 minutes
[CS5340] Monte Carlo Sampling
Motivation
intractable integration problems
- Normalization:
- is intractable to compute in high dimension
- Marinalization:
- Expectation:
Weak law of large numbers
- when
- : sample average
- : real average
Strong law of large numbers
- when
- : sample average
- : real average
Non parametric representation
- represent with drawing samples
- the higher probability of an interval, the more samples are drawn in the intervalf
Rejection Sampling
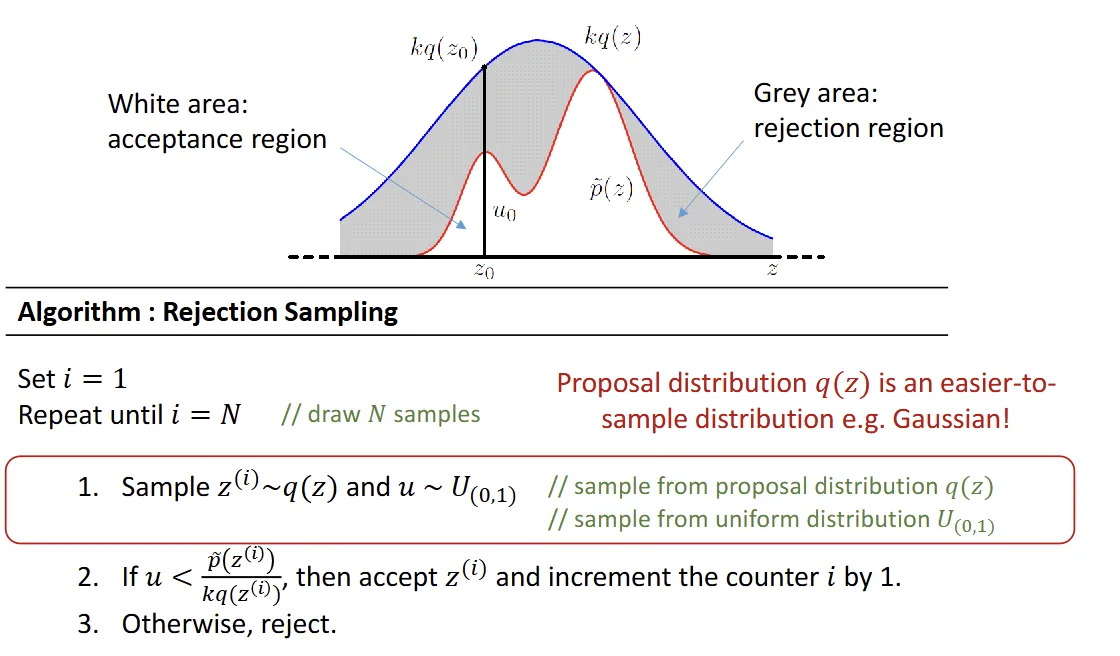
- : target
- : proposal
- set so that
Limitation
- not always possible for to cover all
- if too large, probability of is accepted
Importance Sampling
- approximating expectations of a function w.r.t (target) samples from (proposal)
- therefore importance weight
- but is hard to get , is easy to get (unnormalized)
- ,
- ,
Limitation
- not able to cover everything in the target distribution
- weight may be dominated by a few having large numbers
Ancestral Sampling
- all weights
- starts with root nodes (easy to sample)
- troublesome if loop randomly initialize, but may not converge
MCMC
- spend more time in the most important regions.
- use adaptive proposals: use instead of
- : the previous sample
- : the new sample

Burn-In period
- initial samples may be useles
- discard the first few samples (e.g 1000)
Markov Chain properties
- Homogeneous: fixed transition matrix
- Stationary & limiting distribution: (will eventually converge)
- Irreducibility: at any state, there’s a probability to visit all other states (will not get stuck at a state)
- Aperiodicity: won’t get trapped in a cycle
- Ergodic: Irreducibility + Aperiodicity. MCMC algorithms must satisfy ergodic
- Detailed balance (Reversibility):
- Metropolis-Hasting works because it satisfies detailed balance
Metropolis Algorithm
- a special case of the Metropolis-Hasting
- random walk
- acceptance probability
Gibbs Sampling
- a special case of the Metropolis-Hasting
- acceptance probability is always 1

- condition on all other nodes
- use Markov Blanket (parents, childrens & co-parents) or degree neighbor for MRF
After we have samples:
- : count # of and
- becomes statistic
[CS5340] Monte Carlo Sampling
https://itsjeremyhsieh.github.io/posts/cs5340-9-mcmc/