[CS5340] Hidden Markov Models
HMM#
- an extension of mixture model
- choice of mixture component depends on the previous observation
- latent variables {Z1,...,Zn−1,Zn,...} form a Markov Chain, where the current state Zn is dependent on the previous state Zn−1
- Zn+1⊥Zn−1∣Zn
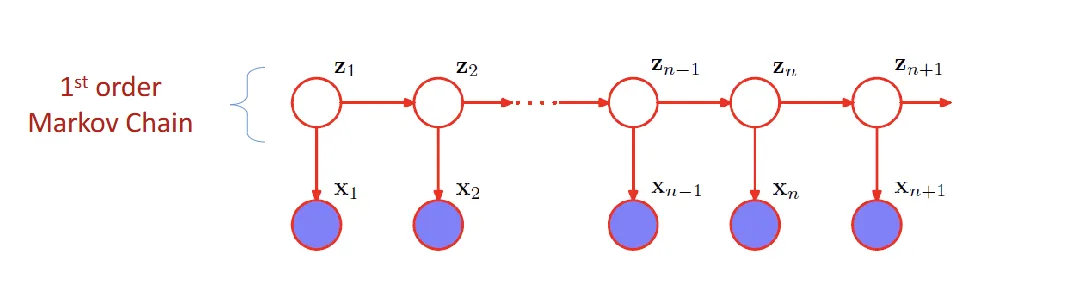
- p(x1,...,xN,Z1,...ZN)=p(Z1)∏n=2Np(Zn∣Zn−1)∏n=1Np(Xn∣Zn)
Transition probabilities#
- 1-of-K coding
- describe which component of the mixture model is responsible for generating the corresponding xn
- Zn∈0,1K, p(Zn∣Zn−1) is a K×K matrix. (A)
- Ajk=p(Zn,k=1∣Zn−1,j=1)
- Ajk: state j to state k
- Zn,k=1: Zn is state k
- Zn−1,j=1: Zn−1 is state j
- 0≤Ajk≤1, ∑KAjk=1
- p(Zn∣Zn−1,A)=∏k=1K∏j=1KAjkZn−1,j×Zn,k
- Zn is state k and Zn−1 is state j
- p(Z1∣π)=∏k=1KπkZ1,k where ∑Kπk=1
- πk: probability of categorical distribution
Emission probability#
- p(Xn∣Zn,ϕ)
- ϕ: parameters governing the distribution
- p(xn∣Zn,ϕ)=∏k=1Kp(xn∣ϕ)nkZ
- Zn is k state, only one Znk will be 1
Homogeneous Model#
- all conditional distributions governing latent variables share the same parameters A
- all emission distributions share the same parameters ϕ
Maximum likelihood#
- now we want to find the maximum likelihood p(x∣θ)=∑Zp(x,z∣θ)
- NO closed-form solutions
- ⇒ use EM algorithm
EM algorithm on HMM#
- Initialization of parameters θold
- E-step: find Q(θ,θold)=∑Zp(z∣x,θold)ln p(x,z∣θ)
- we define:
- r(zn)=p(zn∣x,θold)
- r(znk): conditional probability of znk=1
- =E[znk]=∑znr(zn)znk
- znk=1 when k=k
- ξ(zn−1,zn)=p(zn−1,zn∣x,θold)
- ξ(zn−1,j,zn,k)=E[zn−1,j,zn,k]=∑zn−1,znξ(zn−1,zn)zn−1,jzn,k
- our goal is to compute
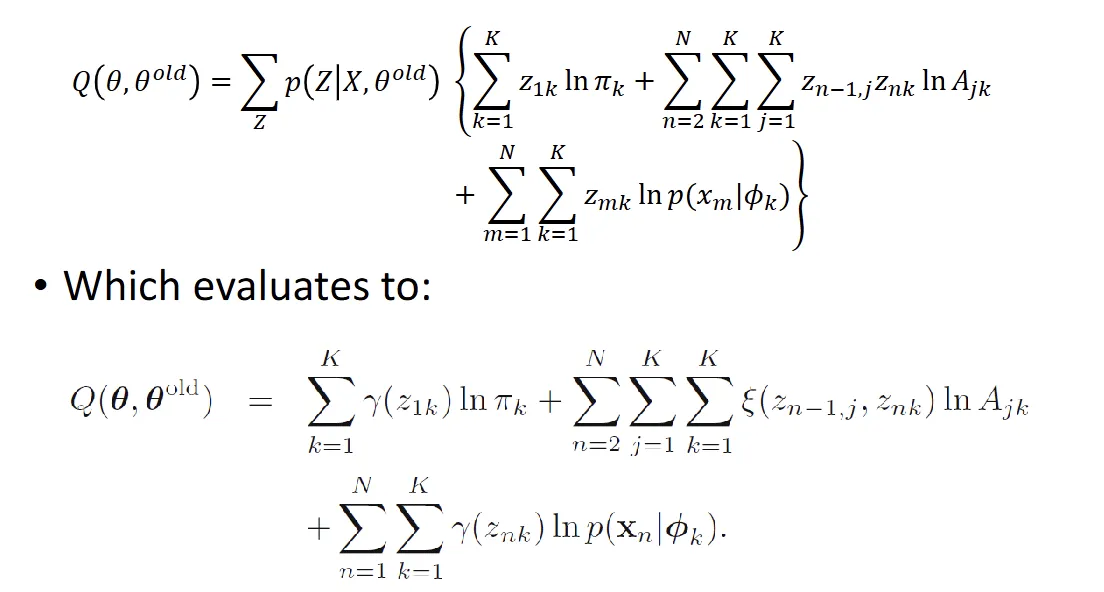
- therefore to find r(zn) and ξ(zn−1,j,zn,k)


- using the Forward-Backward algorithm to find α and β
- α(zn)=p(xn∣zn)∑zn−1α(zn−1)p(zn∣zn−1
- β(zn)=∑zn−1β(zn+1)p(xn+1∣zn+1p(zn+1∣zn)
- α(z1,k) for k=1,...,K =πkp(x1∣ϕk)
- β(zn)=1
- M-step: maximize Q(θ,θold) w.r.t θ={π,A,ϕ}
- πk=∑j=1Kr(z1j)r(z1k)
- Ajk=∑l=1K∑n=2Nξ(zn−1,j,zn,k)∑n=2Nξ(zn−1,jzn,l)
Scaling Factor (for normalization)#
- values of α(zn) can go to 0 exponentially quickly
- α^(zn)=p(zn∣x1,...,xN)=p(x1,...,xN)α(zn)=Cnα(zn)
- Cn=p(x1,...,xN)
- β^(zn)=Cn+1β(zn)
- ⇒
- r(zn)=α^(zn)β^(zn)
- ξ(zn−1,zn)=Cn−1α^(zn−1)p(xn∣zn)p(zn∣zn−1)β^(zn)
Viterbi Algorithm#
- simply the max-sum algorithm performed on HMM