[CS5340] Variation Autoencoder & Diffusion Model
Discriminative model#
- posterior p(Ck∣X)
- map x to Ck (class)
Generative model#
- likelihood p(X∣Ck)
- sampling from the distribution
- can generate data points in input space
- p(x,z∣θ)=p(x∣z,θ)p(z)
- sampling from the prior z p(z) e.g: z = Bedroom
- generate new image from likelihood p(x∣z=Bedroom)
- define prior p(z), deterministic function f(z;θ):z×θ→x
- optimize θ: maximize likelihood p(x∣θ)=infp(x∣z,θ)p(z)dz, where p(x∣z,θ)=N(x∣f(z,θ),σ2I)
- but z is high dimension, intractable
- we suppose p(z)=N(0,I)
- learn f(z,θ) in deep neural network
f(z;θ):z×θ→x#
- consider lnp(x∣z,θ)=lnN(x∣f(z;θ),σ2I)=−∣x−f(z;θ)∣2+const.
- lnp(x)=∑zq(z∣x)lnp(x) (encoder) =∑zq(z∣x)lnq(z∣x)p(x,z) which is the lowerbound (L(q,θ)) +∑zq(z∣x)lnp(z∣x)q(z∣x) (is the KL[q(z∣x)∣∣p(z∣x)]≥0)
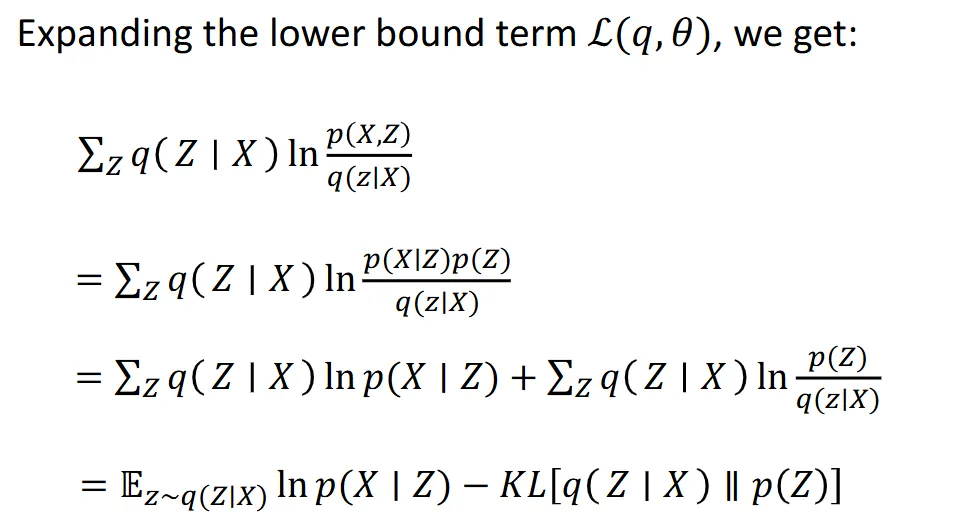
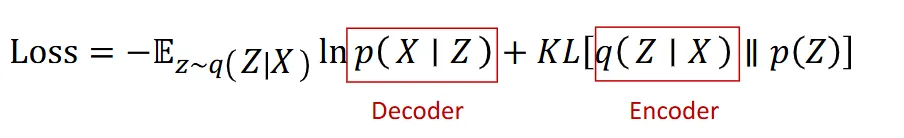
- but gradient =▽(lnp(x∣z))−KL[q(z∣x)∣∣p(z)]]
- q(z∣x) is not trained
Reparameterization Trick#

Diffusion Model#
- Encoder: data sample x, map it through a series of intermediate latent variables. (add noise)
- no learning
- x→Z1→Z2→...→ZT
- Decoder: starting with ZT, map back to x
- deep network
- ZT→ZT−1→...→Z1→x
Encoder (Diffusion)#
Z1=1−β1×x+β1×ϵ1 (noise from normal distribution)
Zt=1−βt×Zt−1+βt×ϵt
⇒q(Z1∣x)=Norm[1−β1x,β1I]
q(Z1...T∣x)=q(Z1∣x)∏t=1Tq(Zt∣Zt−1)
we want to get zt directly from x
Zt=αt×x+q−αt×ϵ, αt=∏s=1t1−βs
q(Zt∣x)=NormZt[αt×x,(q−αt)I]
Decoder (learn the reverse process)#
- approx Pr(ZT)=NormZT[0,T]
Pr(Zt−1∣Zt,ϕt)=NormZt−1[ft[Zt,ϕt],σt2I]
Pr(x∣Z1,ϕt)=Normx[f1[Z1,ϕ1],σ12I] 
- final lost function:
