100 words
1 minutes
[CS5242] Deep CNN Architectures
How do we initiate the weights to prevent vanish/ explode?
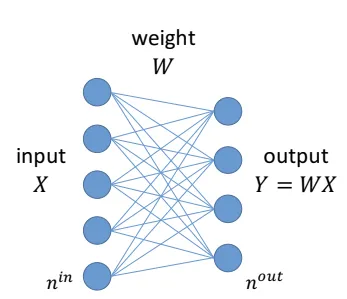
- Forward:
- Backward:
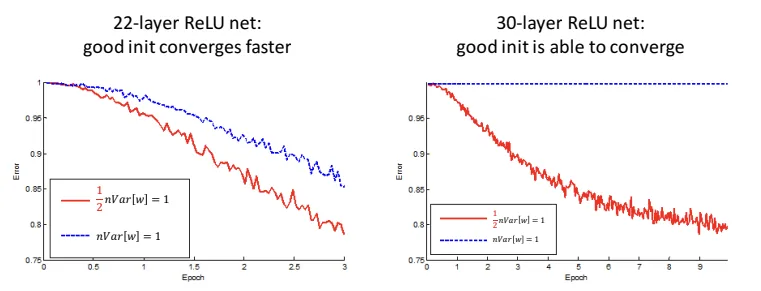
- initiate or
- ReLU: or
Deep Residual Learning
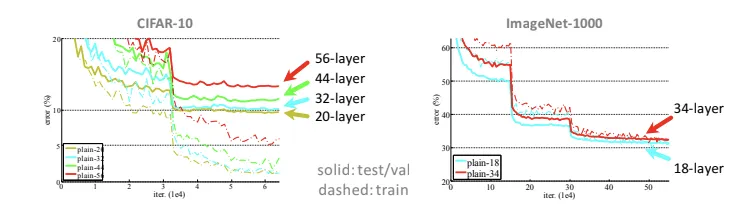
We cannot simply stack layers, or we’ll have optimization difficulties
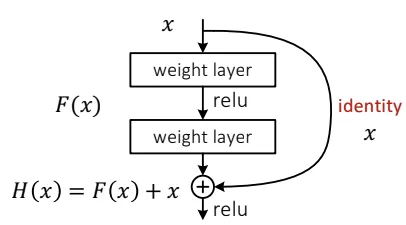
- just learn the change (residue)
- RESNET-34 structure
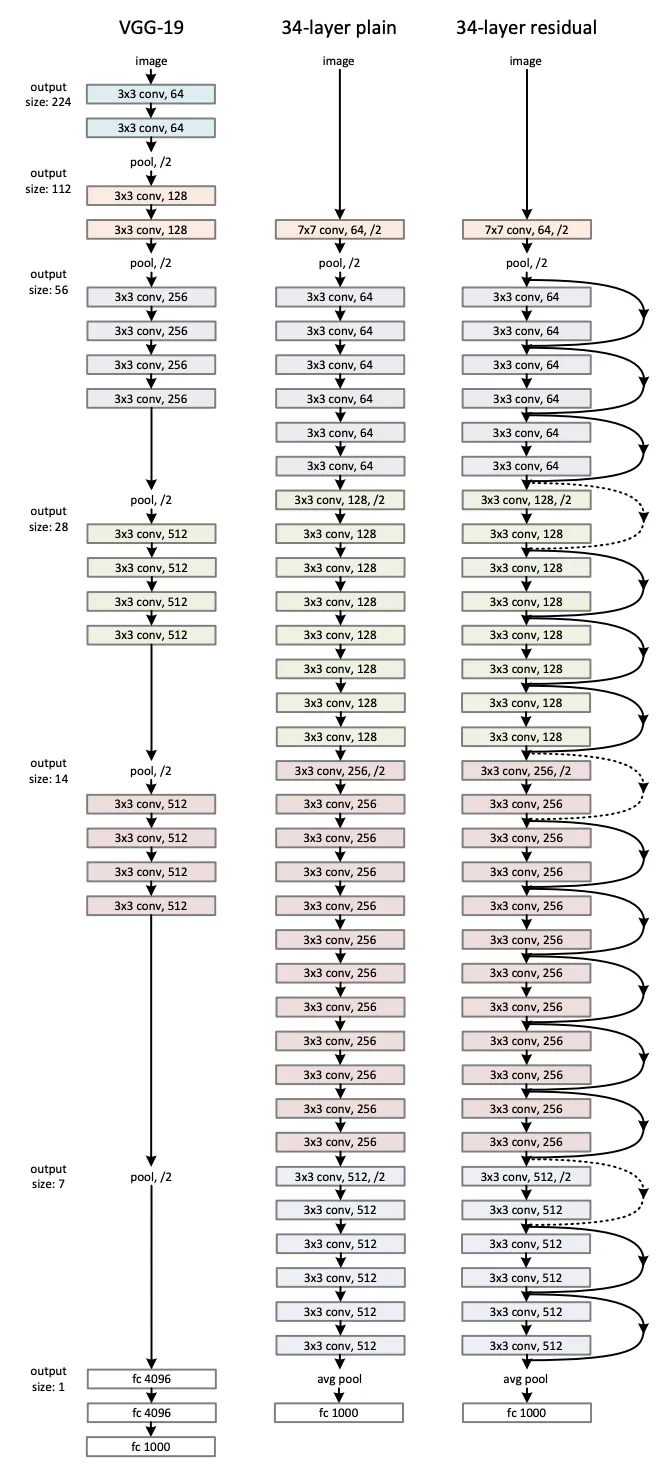
Why use the shortcut?
- Degrading problem
- when the model gets deeper, it becomes more difficult for layers to propagate information from shallow layers and information is lost (degrade rapidly)
- we use shortcuts (identity function)
[CS5242] Deep CNN Architectures
https://itsjeremyhsieh.github.io/posts/cs5242-6-deep-cnn-architecture/