190 words
1 minutes
[CS5242] Training Deep Networks
Activation Function
- perform non-linear feature transformation
- e.g
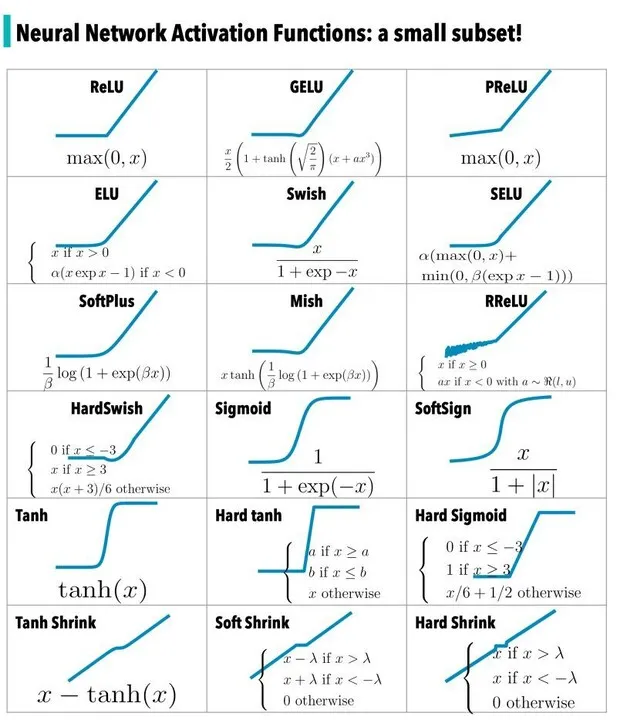
- e.g
- non-linear because linear is too limited
- many linear layers can collapse into one single layer
, where is the non-linear activation function
Stochastic Gradient Discent
Problems with GD:
- Local Optimum: cannot update weights, so next gradients are also 0, each iteration use same (whole) dataset, so there’s no way it can escape
- Efficiency: GD has to load all training samples
randomly pick a (single)training sample to perform BP
- mode efficient
- but much slower, needs more iterations to train
Mini-batch SGD: randomly pick training samples
Converge rate:
Time per iteration:
Training time =
AdaGrad: change learning rate according to gradient
RMSProp: rescale learning rate to remove effect of gradient size, balance between different directions
- , has history information,
, has current information, to balance
- , has history information,
Adam: combining momentum and RMSProp
[CS5242] Training Deep Networks
https://itsjeremyhsieh.github.io/posts/cs5242-3-training-deep-networks/