159 words
1 minutes
[CS5242] Shallow Neural Networks
The Perceptron
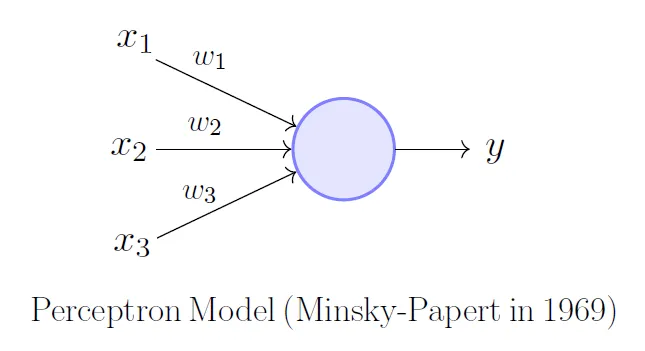
- algorithm to perform image classification
Multi-layer Perceptron (MLP)
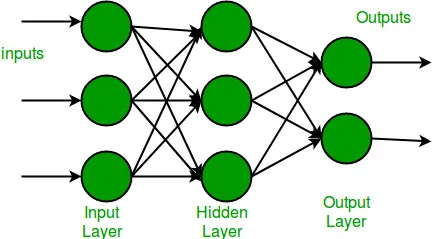
- with fully connected layers
Gradient Descent
- Predict
- Forward pass:
- Compute loss: (L2 loss function)
- Update
- Backward propogation:
- Gradient update:
Under/ Over fitting
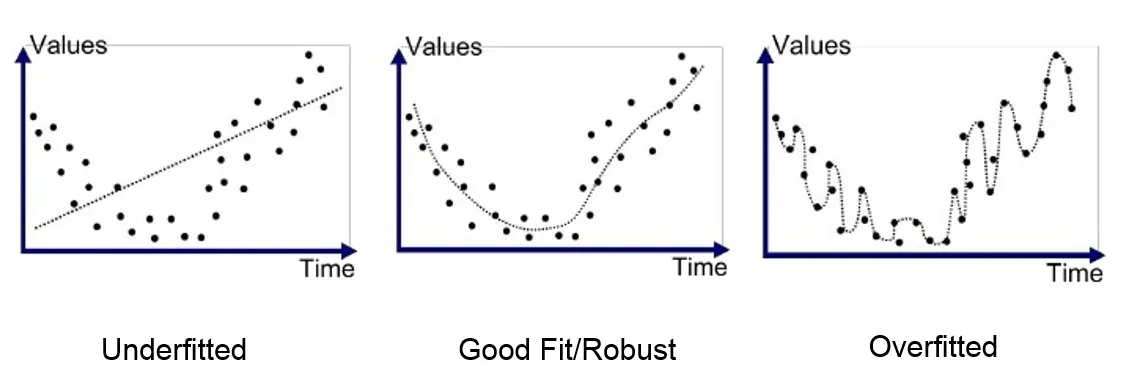
- Underfitting:
- Low model complexity => too simple to fit data
- High bias (constently learn wrong thing)
- Overfitting:
- High model complexity => fits too well to seen data
- High variance (amount of parameter change for different training data)
- Cannot generalize onto new unseen data)
Data Splitting
- Training set for model training
- Validation set for model tuning
- Testing set for testing the final model
K-fold cross validation
- if only few training data
- Divide training set into partitions
- for training, for validation
- Repeat times
Cross entropy loss function
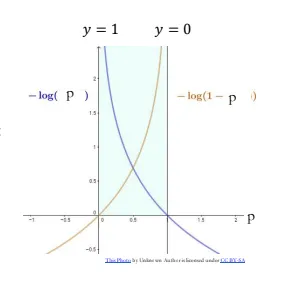
- for ** classification**
- Entropy: the degree of randomness (uncertainty)
- the grater the more uncertain
- , : the true value
- if =>
- if =>
[CS5242] Shallow Neural Networks
https://itsjeremyhsieh.github.io/posts/cs5242-2-shallow-neural-networks/